Grundlagen von Googles Suchalgorithmus
Es folgt eine Übersetzung der ursprünglichen Veröffentlichung des Google-Gründers Larry Page und Sergey Brin über ihr Suchmaschinenprojekt, das später zu Google wurde. Es ist ein wertvoller historischer Text, der die Grundlagen von Googles Suchalgorithmus und seiner Funktionsweise beschreibt.
Die Anatomie einer großen hypertextuellen Websuchmaschine
Abstrakt
In diesem Artikel stellen wir vor Google, ein Prototyp einer groß angelegten Suchmaschine, die viel nutzt der im Hypertext vorhandenen Struktur. Google ist zum Crawlen und zum Crawlen konzipiert Indizieren Sie das Web effizient und erzeugen Sie wesentlich zufriedenstellendere Suchergebnisse als bestehende Systeme. Der Prototyp mit Volltext- und Hyperlink-Datenbank von mindestens 24 Millionen Seiten ist unter http://google.stanford.edu/ verfügbar.
Eine Suchmaschine zu entwickeln ist eine herausfordernde Aufgabe. Suchmaschinen indizieren Dutzende bis Hunderte Millionen von Webseiten mit einer vergleichbaren Anzahl unterschiedlicher Begriffe. Sie Antworten jeden Tag Dutzende Millionen Anfragen. Trotz der Bedeutung des Großmaßstabs Obwohl es Suchmaschinen im Internet gibt, wurde nur sehr wenig wissenschaftliche Forschung betrieben auf sie. Aufgrund des rasanten Fortschritts in der Technologie und der Verbreitung des Internets Die Erstellung einer Websuchmaschine unterscheidet sich heute stark von der vor drei Jahren. Dieses Dokument bietet eine ausführliche Beschreibung unserer groß angelegten Websuche Motor – die erste derart detaillierte öffentliche Beschreibung, die wir bisher kennen.
Abgesehen von den Problemen der Skalierung Traditionelle Suchtechniken für Daten dieser Größenordnung gibt es neue technische Herausforderungen bei der Nutzung der zusätzlichen Informationen im Hypertext, um bessere Suchergebnisse zu erzielen. Dieses Papier befasst sich damit Frage, wie man ein praktisches Großsystem aufbaut, das die Vorteile nutzen kann die zusätzlichen Informationen im Hypertext. Auch wir schauen uns das Problem an wie man effektiv mit unkontrollierten Hypertextsammlungen umgeht Jeder kann alles veröffentlichen, was er will.Schlüsselwörter : World Wide Web, Suchmaschinen, Informationen Abruf, PageRank, Google
1. Einleitung
(Hinweis: Es gibt zwei Versionen dieses Dokuments – eine längere Vollversion und eine kürzere gedruckte Version. Die Vollversion ist auf der verfügbar im Internet und auf der Konferenz-CD-ROM.)
Das Internet stellt die Informationsbeschaffung vor neue Herausforderungen. Die Summe Die Anzahl der Informationen im Internet wächst rasant, ebenso wie die Anzahl neue Benutzer, die in der Kunst der Webrecherche unerfahren sind. Die Leute werden es wahrscheinlich tun Surfen Sie im Internet mithilfe des Link-Graphs, oft beginnend mit qualitativ hochwertigen Links gepflegte Indizes wie Yahoo! oder mit Suchmaschinen. Von Menschen gepflegte Listen decken beliebte Themen effektiv ab sind aber subjektiv, teuer in der Herstellung und Wartung, langsam in der Verbesserung und kann nicht alle esoterischen Themen abdecken. Automatisierte Suchmaschinen, die sich darauf verlassen Beim Keyword-Matching werden in der Regel zu viele Treffer mit geringer Qualität zurückgegeben. Dinge machen Schlimmer noch, einige Werbetreibende versuchen, durch Maßnahmen die Aufmerksamkeit der Menschen zu gewinnen soll automatisierte Suchmaschinen in die Irre führen. Wir haben eine Großanlage gebaut Suchmaschine, die viele Probleme bestehender Systeme angeht. Dabei wird die zusätzliche Struktur im Hypertext besonders intensiv genutzt um Suchergebnisse mit wesentlich höherer Qualität bereitzustellen. Wir haben unseren Systemnamen gewählt, Google, weil es eine gebräuchliche Schreibweise von Googol ist, oder 10 100 und passt gut zu unserem Ziel, sehr große Suchmaschinen aufzubauen.
1.1 Web-Suchmaschinen – Ausbau: 1994–2000
Die Suchmaschinentechnologie musste drastisch skalieren, um mithalten zu können das Wachstum des Webs. Im Jahr 1994 wurde eine der ersten Websuchmaschinen, die World Wide Web-Wurm (WWWW) [McBryan 94] verfügte über einen Index von 110.000 Webseiten und über das Internet zugänglichen Dokumenten. Im November 1997 gaben die Top-Suchmaschinen an, ab 2 Millionen zu indizieren (WebCrawler) auf 100 Millionen Webdokumente (von Search Motoruhr) . Es ist absehbar, dass bis zum Jahr 2000 eine umfassende Der Index des Webs wird über eine Milliarde Dokumente enthalten. Gleichzeitig, Auch die Zahl der Suchanfragen, die Suchmaschinen verarbeiten, ist unglaublich gestiegen. In März und April 1994 erhielt der World Wide Web-Wurm durchschnittlich ca 1500 Anfragen pro Tag. Im November 1997 behauptete Altavista, es sei grob vorgegangen 20 Millionen Anfragen pro Tag. Mit der steigenden Anzahl von Benutzern auf der Web und automatisierte Systeme, die Suchmaschinen abfragen, ist es wahrscheinlich Top-Suchmaschinen verarbeiten täglich Hunderte Millionen Suchanfragen bis zum Jahr 2000. Das Ziel unseres Systems ist es, viele der Probleme anzugehen, sowohl in der Qualität als auch in der Skalierbarkeit, eingeführt durch die Skalierung der Suchmaschinentechnologie zu solch außergewöhnlichen Zahlen.
1.2. Google: Skalierung mit dem Web
Die Entwicklung einer Suchmaschine, die sich sogar an das heutige Web anpassen lässt, bietet viele Möglichkeiten Herausforderungen. Zum Sammeln der Webdokumente ist eine schnelle Crawling-Technologie erforderlich und halten Sie sie auf dem neuesten Stand. Der Lagerraum muss effizient zum Lagern genutzt werden Indizes und optional die Dokumente selbst. Das Indexierungssystem müssen Hunderte Gigabyte an Daten effizient verarbeiten. Abfragen müssen sein schnell verarbeitet, mit einer Geschwindigkeit von Hunderten bis Tausenden pro Sekunde.
Diese Aufgaben werden mit dem Wachstum des Webs immer schwieriger. Jedoch, Die Hardwareleistung und die Kosten haben sich erheblich verbessert und können dies teilweise ausgleichen Die Schwierigkeit. Es gibt jedoch einige bemerkenswerte Ausnahmen hiervon Fortschritt wie Festplattensuchzeit und Betriebssystemrobustheit. Beim Entwerfen Google, wir haben sowohl die Wachstumsrate des Webs als auch der Technologie berücksichtigt Änderungen. Google ist so konzipiert, dass es sich gut auf extrem große Datenmengen skalieren lässt. Es nutzt den Speicherplatz effizient zum Speichern des Index. Seine Datenstrukturen sind für einen schnellen und effizienten Zugriff optimiert (siehe Abschnitt 4.2 ). Darüber hinaus gehen wir davon aus, dass die Kosten für die Indizierung und Speicherung von Text oder HTML irgendwann sinken werden Rückgang im Verhältnis zum verfügbaren Betrag (siehe Anhang) . B ). Dies führt zu günstigen Skalierungseigenschaften für zentralisierte Systeme wie Google.
1.3 Designziele
1.3.1 Verbesserte Suchqualität
Unser Hauptziel ist es, die Qualität von Websuchmaschinen zu verbessern. Im Jahr 1994 Einige Leute glaubten, dass ein vollständiger Suchindex dies ermöglichen würde um etwas leicht zu finden. Laut Best of the Web 1994 – Navigators: „Der beste Navigationsdienst sollte Machen Sie es einfach, fast alles im Web zu finden (sobald alle Daten eingegeben wurden).“ Das Web von 1997 ist jedoch ganz anders. Jeder, der eine Suche verwendet hat Motor vor kurzem, kann leicht bezeugen, dass die Vollständigkeit des Index ist nicht der einzige Faktor für die Qualität der Suchergebnisse. „Junk-Ergebnisse“ verwaschen oft alle Ergebnisse, an denen ein Benutzer interessiert ist. Tatsächlich ab November 1997, nur eine der vier besten kommerziellen Suchmaschinen findet selbst (gibt als Antwort auf seinen Namen oben eine eigene Suchseite zurück). zehn Ergebnisse). Eine der Hauptursachen für dieses Problem ist die Anzahl der Dokumente in den Indizes ist um viele Größenordnungen gestiegen, Die Fähigkeit des Benutzers, Dokumente anzusehen, ist jedoch nicht beeinträchtigt. Die Leute sind immer noch nur Ich bin bereit, mir die ersten paar Dutzend Ergebnisse anzusehen. Aus diesem Grund, wie die Da die Sammlungsgröße wächst, benötigen wir Werkzeuge mit sehr hoher Präzision (Anzahl). der zurückgegebenen relevanten Dokumente, beispielsweise in den Top 10 der Ergebnisse). In der Tat, Wir möchten, dass unser Begriff „relevant“ nur die allerbesten Dokumente umfasst da es Zehntausende leicht relevanter Dokumente geben kann. Das Sehr hohe Präzision ist wichtig, auch auf Kosten der Erinnerung (die Gesamtheit). Anzahl relevanter Dokumente, die das System zurückgeben kann). Es gibt ganz ein wenig neuer Optimismus, dass die Verwendung von mehr hypertextuellen Informationen kann dabei helfen, die Suche und andere Anwendungen zu verbessern [ Marchiori 97 ] [ Spertus 97 ] [ Weiss 96 ] [ Kleinberg 98 ]. Insbesondere Linkstruktur [ Seite 98 ] und Linktext liefern viele Informationen für Relevanzbeurteilungen und Qualitätsfilterung. Google nutzt sowohl der Linkstruktur als auch des Ankertextes (siehe Abschnitte 2.1 und 2.2 ).
1.3.2 Akademische Suchmaschinenforschung
Neben dem enormen Wachstum ist das Web auch zunehmend kommerziell geworden im Laufe der Zeit. Im Jahr 1993 befanden sich 1,5 % der Webserver auf .com-Domains. Diese Nummer stieg 1997 auf über 60 %. Gleichzeitig sind Suchmaschinen migriert vom akademischen bis zum kommerziellen Bereich. Bisher die meisten Suchmaschinen Die Entwicklung hat bei Unternehmen stattgefunden, in denen kaum technische Veröffentlichungen vorliegen Einzelheiten. Dies führt dazu, dass die Suchmaschinentechnologie weitgehend im Dunkeln bleibt Kunst und werbeorientiert sein (siehe Anhang A ). Mit Google, wir haben das starke Ziel, mehr Entwicklung und Verständnis voranzutreiben in den akademischen Bereich.
Ein weiteres wichtiges Designziel bestand darin, Systeme mit angemessenen Zahlen zu bauen der Menschen tatsächlich nutzen können. Die Nutzung war uns wichtig, weil wir denken Bei einigen der interessantesten Forschungsarbeiten wird es darum gehen, die enorme Bandbreite zu nutzen Menge an Nutzungsdaten, die von modernen Websystemen verfügbar sind. Zum Beispiel, Jeden Tag werden mehrere zehn Millionen Suchanfragen durchgeführt. Jedoch, Es ist sehr schwierig, diese Daten zu erhalten, vor allem weil sie berücksichtigt werden kommerziell wertvoll.
Unser letztes Designziel war es, eine Architektur zu schaffen, die unterstützen kann neuartige Forschungsaktivitäten zu großen Webdaten. Zur Unterstützung neuartiger Forschung verwendet, speichert Google alle tatsächlich gecrawlten Dokumente komprimiert bilden. Eines unserer Hauptziele bei der Gestaltung von Google war die Einrichtung einer Umgebung wo andere Forscher schnell eingreifen und große Teile davon verarbeiten können Web und liefern interessante Ergebnisse, die sehr schwierig gewesen wären anders produzieren. In der kurzen Zeit, in der das System in Betrieb war, gab es solche Es gab bereits mehrere Artikel, die von Google generierte Datenbanken verwendeten, und viele andere sind im Gange. Ein weiteres Ziel, das wir haben, ist die Einrichtung eines Spacelab-ähnlichen Systems Umgebung, in der Forscher oder sogar Studenten interessante Vorschläge machen und umsetzen können Experimente mit unseren umfangreichen Webdaten.
2. Systemfunktionen
Die Google-Suchmaschine verfügt über zwei wichtige Funktionen, die ihr bei der Produktion helfen hochpräzise Ergebnisse. Erstens nutzt es die Linkstruktur des Web, um für jede Webseite ein Qualitätsranking zu berechnen. Dieses Ranking heißt PageRank und wird ausführlich in [Seite 98] beschrieben. Zweitens nutzt Google Link zur Verbesserung der Suchergebnisse.
2.1 PageRank: Ordnung ins Web bringen
Das Zitierdiagramm (Link) des Webs ist eine wichtige Ressource in bestehenden Websuchmaschinen weitgehend ungenutzt geblieben. Wir haben Karten erstellt enthält bis zu 518 Millionen dieser Hyperlinks, eine bedeutende Stichprobe von allen. Diese Karten ermöglichen eine schnelle Berechnung des „PageRank“ einer Webseite. ein objektives Maß für die Zitierbedeutung, das gut mit übereinstimmt die subjektive Vorstellung der Menschen von Wichtigkeit. Aufgrund dieser Korrespondenz PageRank ist eine hervorragende Möglichkeit, die Ergebnisse von Web-Keyword-Suchen zu priorisieren. Für die beliebtesten Themen gibt es eine einfache, eingeschränkte Textübereinstimmungssuche zu Webseitentiteln funktioniert hervorragend, wenn PageRank den Ergebnissen Priorität einräumt (Demo verfügbar unter google.stanford.edu ). Für die Art der Volltextsuche im Hauptsystem von Google: PageRank hilft auch sehr.
2.1.1 Beschreibung der PageRank-Berechnung
Akademische Zitierliteratur wurde größtenteils durch Zählen auf das Internet angewendet Zitate oder Backlinks zu einer bestimmten Seite. Dies gibt eine gewisse Annäherung an die Wichtigkeit oder Qualität einer Seite. PageRank erweitert diese Idee, indem es nicht zählt Links von allen Seiten gleichermaßen und durch Normalisierung anhand der Anzahl der Links auf einer Seite. PageRank ist wie folgt definiert:
Wir gehen davon aus, dass Seite A Seiten T1…Tn hat, die darauf verweisen (d. h. sind Zitate). Der Parameter d ist ein einstellbarer Dämpfungsfaktor 0 und 1. Normalerweise setzen wir d auf 0,85. Weitere Einzelheiten zu d finden Sie im nächsten Abschnitt. Außerdem ist C(A) als die Anzahl der ausgehenden Links definiert Seite A. Der PageRank einer Seite A ergibt sich wie folgt: PR(A) = (1-d) + d (PR(T1)/C(T1) + … + PR(Tn)/C(Tn))
Beachten Sie, dass die PageRanks eine Wahrscheinlichkeitsverteilung über das Web bilden Seiten, so dass die Summe aller PageRanks aller Webseiten eins ist.
PageRank oder PR(A) können mithilfe eines einfachen iterativen Algorithmus berechnet werden. und entspricht dem Haupteigenvektor der normalisierten Linkmatrix des Webs. Außerdem kann ein PageRank für 26 Millionen Webseiten berechnet werden ein paar Stunden auf einer mittelgroßen Workstation. Es gibt viele weitere Details die den Rahmen dieser Arbeit sprengen.
2.1.2 Intuitive Begründung
PageRank kann als Modell des Benutzerverhaltens betrachtet werden. Da gehen wir davon aus ist ein „Zufallssurfer“, der zufällig eine Webseite erhält und weiter klickt auf Links, klickt nie auf „Zurück“, wird aber irgendwann gelangweilt und fängt an eine weitere zufällige Seite. Die Wahrscheinlichkeit, dass der zufällige Surfer eine Seite besucht ist sein PageRank. Und der d- Dämpfungsfaktor ist die Wahrscheinlichkeit bei Auf jeder Seite langweilt sich der „Zufallssurfer“ und er fordert eine andere, zufällige Seite an Seite. Eine wichtige Variante besteht darin, nur den Dämpfungsfaktor d hinzuzufügen auf eine einzelne Seite oder eine Gruppe von Seiten. Dies ermöglicht eine Personalisierung und kann es nahezu unmöglich machen, das System absichtlich in die Irre zu führen um einen höheren Rang zu erreichen. Wir haben mehrere andere Erweiterungen für PageRank, siehe auch [ Seite 98 ].
Eine weitere intuitive Begründung ist, dass eine Seite einen hohen PageRank haben kann wenn es viele Seiten gibt, die darauf verweisen, oder wenn es einige Seiten gibt, die darauf verweisen Zeigen Sie darauf und haben Sie einen hohen PageRank. Intuitiv, Seiten, die gut sind An vielen Stellen im Internet zitierte Texte sind einen Blick wert. Auch Seiten die vielleicht nur ein Zitat aus so etwas wie dem Yahoo! enthalten Auch die Homepage ist grundsätzlich einen Blick wert. Wenn eine Seite nicht von hoher Qualität war, oder ein defekter Link war, ist es sehr wahrscheinlich, dass die Homepage von Yahoo dies nicht tun würde Link dazu. PageRank behandelt diese beiden Fälle und alles dazwischen durch rekursive Weitergabe von Gewichten durch die Linkstruktur des Webs.
2.2 Ankertext
Der Text von Links wird in unserer Suchmaschine besonders behandelt. Am meisten Suchmaschinen verknüpfen den Text eines Links mit der Seite, auf die der Link verweist ist eingeschaltet. Darüber hinaus verknüpfen wir es mit der Seite, auf die der Link verweist. Das hat mehrere Vorteile. Erstens liefern Anker oft genauere Beschreibungen von Webseiten als die Seiten selbst. Zweitens können Anker für Dokumente vorhanden sein die nicht von einer textbasierten Suchmaschine indiziert werden können, wie zum Beispiel Bilder, Programme und Datenbanken. Dadurch ist es möglich, Webseiten zurückzugeben, die wurden nicht wirklich gecrawlt. Beachten Sie, dass Seiten nicht gecrawlt wurden kann zu Problemen führen, da sie vor ihrer Veröffentlichung nie auf ihre Gültigkeit überprüft werden an den Benutzer zurückgegeben. In diesem Fall kann die Suchmaschine sogar ein zurückgeben Seite, die eigentlich nie existierte, auf die aber Hyperlinks verwiesen. Jedoch, Es ist möglich, die Ergebnisse zu sortieren, sodass dieses spezielle Problem selten auftritt das passiert.
Diese Idee, Ankertext an die Seite weiterzugeben, auf die er verweist, wurde umgesetzt im World Wide Web Wurm [ McBryan 94 ] vor allem, weil Es hilft bei der Suche nach Nichttextinformationen und erweitert den Suchbereich um weniger heruntergeladene Dokumente. Wir verwenden die Ankerausbreitung hauptsächlich, weil Ankertext kann dazu beitragen, bessere Ergebnisse zu erzielen. Ankertext verwenden effizient durchzuführen ist aufgrund der großen Datenmengen technisch schwierig die bearbeitet werden müssen. In unserem aktuellen Crawl von 24 Millionen Seiten, Wir hatten über 259 Millionen Anker, die wir indexiert haben.
2.3 Weitere Funktionen
Abgesehen von PageRank und der Verwendung von Ankertext bietet Google noch mehrere andere Merkmale. Erstens verfügt es über Standortinformationen für alle Treffer und macht es so Umfangreiche Nutzung der Nähe bei der Suche. Zweitens verfolgt Google einige davon visuelle Präsentationsdetails wie die Schriftgröße von Wörtern. Wörter in einem größeren oder fettere Schriftart werden höher gewichtet als andere Wörter. Drittens, vollständiges Roh-HTML Anzahl der Seiten ist in einem Repository verfügbar.
3 Verwandte Arbeiten
Die Suchforschung im Web hat eine kurze und prägnante Geschichte. Das weltweite Web-Wurm (WWWW) [McBryan 94] war eine der ersten Websuchmaschinen. Es wurde anschließend befolgt von mehreren anderen akademischen Suchmaschinen, von denen viele mittlerweile öffentlich sind Firmen. Im Vergleich zum Wachstum des Webs und der Bedeutung von Suchmaschinen Es gibt nur sehr wenige Dokumente über aktuelle Suchmaschinen [ Pinkerton 94 ]. Laut Michael Mauldin (Chefwissenschaftler, Lycos Inc) [Mauldin] : „Die verschiedenen Dienste (einschließlich Lycos) hüten die Einzelheiten hierzu streng Datenbanken”. Es wurde jedoch ziemlich viel an bestimmten Funktionen gearbeitet von Suchmaschinen. Besonders gut vertreten sind Arbeiten, die Ergebnisse erzielen können durch Nachbearbeitung der Ergebnisse bestehender kommerzieller Suchmaschinen, oder kleine „individualisierte“ Suchmaschinen erstellen. Endlich gibt es Es wurde viel über Informationsabrufsysteme geforscht, insbesondere über gut kontrollierte Sammlungen. In den nächsten beiden Abschnitten besprechen wir einige davon Bereiche, in denen diese Forschung ausgeweitet werden muss, um im Internet besser zu funktionieren.
3.1 Informationsabruf
Die Arbeit an Informationsabrufsystemen reicht viele Jahre zurück und ist gut entwickelt [ Witten 94 ]. Allerdings ist der Großteil der Forschung Bei Informationsabrufsystemen handelt es sich um kleine, gut kontrollierte homogene Systeme Sammlungen wie Sammlungen wissenschaftlicher Arbeiten oder Nachrichtenbeiträge ein verwandtes Thema. Tatsächlich ist der primäre Maßstab für die Informationsbeschaffung, Die Text Retrieval Conference [ TREC 96 ] verwendet ein faires kleine, gut kontrollierte Sammlung für ihre Benchmarks. Das „Sehr Große“. Corpus“-Benchmark beträgt nur 20 GB im Vergleich zu den 147 GB aus unserem Crawl 24 Millionen Webseiten. Dinge, die auf TREC gut funktionieren, werden oft nicht produziert gute Ergebnisse im Internet. Beispielsweise versucht es das Standard-Vektorraummodell um das Dokument zurückzugeben, das der angegebenen Abfrage am nächsten kommt dass sowohl die Abfrage als auch das Dokument Vektoren sind, die durch das Vorkommen ihres Wortes definiert werden. Im Web werden mit dieser Strategie häufig sehr kurze Dokumente zurückgegeben Frage plus ein paar Worte. Wir haben zum Beispiel eine große Suchmaschine gesehen Geben Sie eine Seite zurück, die nur „Bill Clinton Sucks“ und ein Bild aus einem „Bill“ enthält Clinton“-Abfrage. Einige argumentieren, dass Benutzer im Internet genauere Angaben machen sollten Geben Sie ein, was sie wollen, und fügen Sie ihrer Anfrage weitere Wörter hinzu. Wir sind vehement anderer Meinung mit dieser Position. Wenn ein Benutzer eine Anfrage wie „Bill Clinton“ stellt, sollte er dies tun Erzielen Sie vernünftige Ergebnisse, da es eine enorme Menge an hoher Qualität gibt Informationen zu diesem Thema verfügbar. Angesichts solcher Beispiele glauben wir dass die Standardarbeit zum Abrufen von Informationen erweitert werden muss, um damit umzugehen effektiv mit dem Web.
3.2 Unterschiede zwischen dem Web und gut kontrollierten Sammlungen
Das Web ist eine riesige Sammlung völlig unkontrollierter heterogener Dokumente. Dokumente im Internet weisen extreme interne Unterschiede auf. und auch in den externen Metainformationen, die möglicherweise verfügbar sind. Für Beispielsweise unterscheiden sich Dokumente intern in ihrer Sprache (sowohl menschlicher als auch menschlicher Sprache). Programmierung), Vokabular (E-Mail-Adressen, Links, Postleitzahlen, Telefonnummern, Produktnummern), Typ oder Format (Text, HTML, PDF, Bilder, Sounds) und können sogar maschinell generiert werden (Protokolldateien oder Ausgabe aus einer Datenbank). An Andererseits definieren wir externe Metainformationen als Informationen, die kann auf ein Dokument geschlossen werden, ist aber nicht darin enthalten. Beispiele Zu den externen Metainformationen gehören Dinge wie die Reputation der Quelle, Aktualisierungshäufigkeit, Qualität, Beliebtheit oder Nutzung und Zitate. Nicht nur Die möglichen Quellen externer Metainformationen sind vielfältig, aber die Dinge Die gemessenen Werte schwanken ebenfalls um viele Größenordnungen. Zum Beispiel, Vergleichen Sie die Nutzungsinformationen einer großen Homepage wie der von Yahoo erhält derzeit täglich Millionen von Seitenaufrufen mit unklarem Verlauf Artikel, der möglicherweise alle zehn Jahre einmal aufgerufen wird. Ganz klar, diese beiden Elemente müssen von einer Suchmaschine sehr unterschiedlich behandelt werden.
Ein weiterer großer Unterschied zwischen dem Web und herkömmlichen, gut kontrollierten Geräten Sammlungen bestehen darin, dass es praktisch keine Kontrolle darüber gibt, was Menschen tun können ins Netz stellen. Kombinieren Sie diese Flexibilität, alles zu veröffentlichen, mit dem enormen Einfluss von Suchmaschinen auf die Verkehrslenkung und Unternehmen, die dies absichtlich tun Die Manipulation von Suchmaschinen aus Profitgründen wird zu einem ernsten Problem. Dieses Problem wurde in herkömmlichen geschlossenen Informationen nicht angesprochen Retrieval-Systeme. Es ist auch interessant festzustellen, dass Metadatenbemühungen durchgeführt werden sind bei Web-Suchmaschinen weitgehend gescheitert, da kein Text auf der Seite vorhanden ist Informationen, die dem Benutzer nicht direkt angezeigt werden, werden zur Manipulation der Suche missbraucht Motoren. Es gibt sogar zahlreiche Unternehmen, die sich auf die Manipulation spezialisiert haben Suchmaschinen für Profit.
4 Systemanatomie
Zunächst werden wir eine allgemeine Diskussion über die Architektur führen. Dann, Es gibt einige ausführliche Beschreibungen wichtiger Datenstrukturen. Endlich, Die wichtigsten Anwendungen: Crawling, Indexierung und Suche werden untersucht ausführlich.
 |
4.1 Übersicht über die Google-Architektur
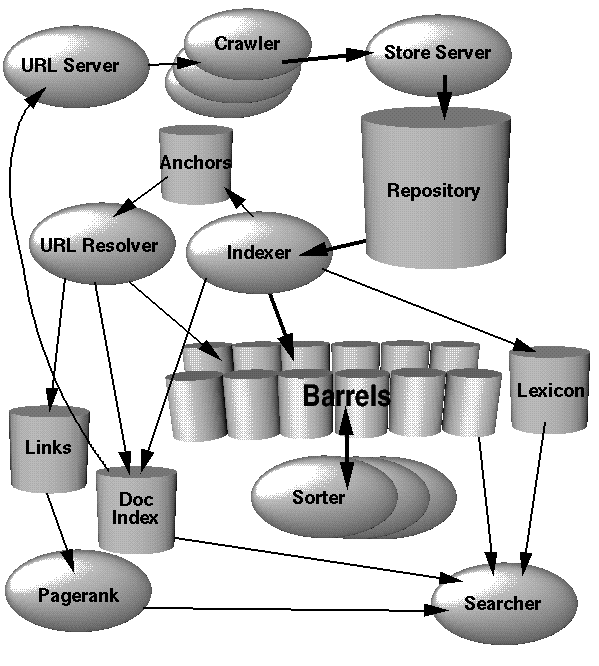
In diesem Abschnitt geben wir einen allgemeinen Überblick über die Funktionsweise des gesamten Systems funktioniert wie in Abbildung 1 dargestellt. In den weiteren Abschnitten werden die Anwendungen erläutert und Datenstrukturen, die in diesem Abschnitt nicht erwähnt werden. Der größte Teil von Google ist implementiert aus Effizienzgründen in C oder C++ geschrieben und kann entweder unter Solaris oder Linux ausgeführt werden.
Bei Google erfolgt das Webcrawlen (Herunterladen von Webseiten) durch mehrere Verteilte Crawler. Es gibt einen URL-Server, an den URL-Listen gesendet werden zu den Crawlern geholt werden. Anschließend werden die abgerufenen Webseiten versendet zum Storeserver. Der Storeserver komprimiert und speichert dann das Web Seiten in ein Repository. Jeder Webseite ist eine sogenannte ID-Nummer zugeordnet eine docID, die immer dann zugewiesen wird, wenn eine neue URL aus einer Webseite geparst wird. Die Indexierungsfunktion wird vom Indexer und Sortierer ausgeführt. Der Indexer erfüllt eine Reihe von Funktionen. Es liest das Repository und dekomprimiert es Dokumente und analysiert sie. Jedes Dokument wird in einen Wortsatz umgewandelt Ereignisse, sogenannte Treffer. Die Treffer erfassen das Wort, die Position im Dokument, eine Annäherung an Schriftgröße und Großschreibung. Der Indexer verteilt Diese Treffer werden in eine Reihe von „Fässern“ geleitet, wodurch ein teilweise sortierter Vorlauf entsteht Index. Der Indexer erfüllt eine weitere wichtige Funktion. Es analysiert zeigt alle Links auf jeder Webseite an und speichert wichtige Informationen darüber sie in einer Ankerdatei. Diese Datei enthält genügend Informationen zur Bestimmung wo jeder Link hin und her zeigt und der Text des Links.
Der URLresolver liest die Ankerdatei und konvertiert relative URLs in absolute URLs und wiederum in docIDs. Es fügt den Ankertext in die ein Vorwärtsindex, der der Dokument-ID zugeordnet ist, auf die der Anker zeigt. Es generiert außerdem eine Datenbank mit Links, bei denen es sich um Paare von DocIDs handelt. Die Links Die Datenbank wird verwendet, um PageRanks für alle Dokumente zu berechnen.
Der Sortierer nimmt die Fässer auf, die nach docID sortiert sind (dies ist eine Vereinfachung, siehe Abschnitt 4.2.5 ) und ordnet sie nach Wort-ID neu, um sie zu generieren der invertierte Index. Dies geschieht an Ort und Stelle, so dass nur wenig temporärer Platz entsteht wird für diesen Vorgang benötigt. Der Sortierer erstellt auch eine Liste von Wort-IDs und Offsets in den invertierten Index. Ein Programm namens DumpLexicon übernimmt Diese Liste wird zusammen mit dem vom Indexer erstellten Lexikon erstellt und generiert ein neues Lexikon, das vom Suchenden verwendet werden soll. Der Sucher wird von einem Web betrieben Server und verwendet das von DumpLexicon erstellte Lexikon zusammen mit dem invertierten Index und die PageRanks zur Beantwortung von Anfragen.
4.2 Wichtige Datenstrukturen
Die Datenstrukturen von Google sind so optimiert, dass eine große Dokumentensammlung möglich ist können mit geringem Aufwand gecrawlt, indiziert und durchsucht werden. Obwohl, CPUs und die Massen-Input-Output-Raten haben sich im Laufe der Jahre dramatisch verbessert, Eine Festplattensuche dauert immer noch etwa 10 ms. Google ist entworfen Festplattensuchvorgänge nach Möglichkeit zu vermeiden, was erhebliche Auswirkungen hatte Einfluss auf die Gestaltung der Datenstrukturen.
4.2.1 BigFiles
BigFiles are virtual files spanning multiple file systems and are addressable by 64 bit integers. The allocation among multiple file systems is handled automatically. The BigFiles package also handles allocation and deallocation of file descriptors, since the operating systems do not provide enough for our needs. BigFiles also support rudimentary compression options.
4.2.2 Repository
 |
Das Repository enthält den vollständigen HTML-Code jeder Webseite. Jede Seite ist komprimiert mit zlib (siehe RFC1950 ). Die Wahl der Komprimierungstechnik ist ein Kompromiss zwischen Geschwindigkeit und Komprimierung Verhältnis. Wir haben die Geschwindigkeit von zlib einer deutlichen Verbesserung der Komprimierung vorgezogen angeboten von bzip . Die Komprimierung Die Bzip-Rate im Repository betrug im Vergleich zu etwa 4 zu 1 Die 3-zu-1-Komprimierung von zlib. Im Repository werden die Dokumente abgelegt nacheinander und werden nach Möglichkeit mit der DocID, der Länge und der URL vorangestellt siehe Abbildung 2. Für das Repository sind keine weiteren Datenstrukturen erforderlich verwendet, um darauf zuzugreifen. Dies hilft bei der Datenkonsistenz und macht Entwicklung viel einfacher; Wir können alle anderen Datenstrukturen daraus neu erstellen nur das Repository und eine Datei, die Crawler-Fehler auflistet.
4.2.3 Dokumentenindex
Der Dokumentenindex speichert Informationen zu jedem Dokument. es ist ein ISAM-Index (Index Sequential Access Mode) mit fester Breite, sortiert nach docID. Die in jedem Eintrag gespeicherten Informationen umfassen den aktuellen Dokumentstatus, einen Zeiger in das Repository, eine Dokumentprüfsumme und verschiedene Statistiken. Wenn das Dokument gecrawlt wurde, enthält es auch einen Zeiger auf eine Variable breite Datei namens docinfo, die ihre URL und ihren Titel enthält. Ansonsten Der Zeiger zeigt auf die URLlist, die nur die URL enthält. Dieses Design Die Entscheidung beruhte auf dem Wunsch nach einer einigermaßen kompakten Datenstruktur. und die Möglichkeit, während einer Suche einen Datensatz in einer einzigen Festplattensuche abzurufen
Zusätzlich gibt es eine Datei, die zur Umwandlung von URLs in docIDs verwendet wird. Es handelt sich um eine sortierte Liste von URL-Prüfsummen mit den entsprechenden docIDs durch Prüfsumme. Um die docID einer bestimmten URL zu finden, muss die Die Prüfsumme der URL wird berechnet und eine binäre Suche anhand der Prüfsummen durchgeführt Datei, um ihre docID zu finden. URLs können im Batch in DocIDs konvertiert werden indem Sie eine Zusammenführung mit dieser Datei durchführen. Dies ist die Technik des URLresolvers Wird verwendet, um URLs in DocIDs umzuwandeln. Dieser Batch-Aktualisierungsmodus ist von entscheidender Bedeutung, weil Andernfalls müssen wir für jeden Link eine Suche durchführen, was eine Festplatte voraussetzt Für unseren 322 Millionen Link-Datensatz würde es mehr als einen Monat dauern.
4.2.4 Lexikon
Das Lexikon hat verschiedene Formen. Eine wichtige Änderung gegenüber Der Vorteil früherer Systeme besteht darin, dass das Lexikon zu einem angemessenen Preis in den Speicher passt Preis. In der aktuellen Implementierung können wir das Lexikon im Speicher behalten auf einer Maschine mit 256 MB Hauptspeicher. Das aktuelle Lexikon enthält 14 Millionen Wörter (obwohl einige seltene Wörter nicht zum Lexikon hinzugefügt wurden). Es besteht aus zwei Teilen – einer Liste der Wörter (verkettet). aber durch Nullen getrennt) und eine Hash-Tabelle mit Zeigern. Für verschiedene Funktionen enthält die Wortliste einige Zusatzinformationen, die darüber hinausgehen Der Umfang dieses Papiers soll vollständig erläutert werden.
4.2.5 Trefferlisten
Eine Trefferliste entspricht einer Liste des Vorkommens eines bestimmten Wortes in ein bestimmtes Dokument, einschließlich Positions-, Schriftart- und Großschreibungsinformationen. Trefferlisten nehmen den größten Teil des Platzes ein, der sowohl im Forward als auch im verwendet wird invertierte Indizes. Aus diesem Grund ist es wichtig, sie als darzustellen effizient wie möglich. Wir haben mehrere Alternativen zur Kodierung in Betracht gezogen Position, Schriftart und Großschreibung – einfache Kodierung (ein Tripel von ganzen Zahlen), eine kompakte Kodierung (eine handoptimierte Zuweisung von Bits) und Huffman-Kodierung. Letztendlich haben wir uns für eine handoptimierte Kompaktkodierung entschieden, da dies erforderlich war weit weniger Platz als die einfache Kodierung und weit weniger Bitmanipulation als Huffman-Codierung. Die Details der Treffer sind in Abbildung 3 dargestellt.
Unsere kompakte Kodierung verwendet zwei Bytes für jeden Treffer. Es gibt zwei Arten von Hits: ausgefallene Hits und einfache Hits. Zu den ausgefallenen Hits gehören Hits, die in vorkommen eine URL, ein Titel, ein Ankertext oder ein Meta-Tag. Zu einfachen Hits gehört alles andere. Ein einfacher Treffer besteht aus einem Großschreibungsbit, einer Schriftgröße und 12 Bits Wortposition in einem Dokument (alle Positionen über 4095 werden beschriftet). 4096). Die Schriftgröße wird relativ zum Rest des Dokuments dargestellt unter Verwendung von drei Bits (tatsächlich werden nur 7 Werte verwendet, da 111 das Flag ist). das signalisiert einen ausgefallenen Hit). Ein ausgefallener Hit besteht aus einem Großschreibungsbit, Die Schriftgröße ist auf 7 eingestellt, um anzuzeigen, dass es sich um einen ausgefallenen Treffer handelt, 4 Bit zum Kodieren die Art des ausgefallenen Treffers und 8 Bits der Position. Für Ankertreffer sind es die 8 Bits der Position werden in 4 Bits für die Position im Anker und 4 Bits für die Position aufgeteilt ein Hash der docID, in der der Anker vorkommt. Dies gibt uns eine begrenzte Phrase Suchen, solange es nicht so viele Anker für ein bestimmtes Wort gibt. Wir gehen davon aus, dass wir die Art und Weise, wie Ankertreffer gespeichert werden, aktualisieren, um mehr zu ermöglichen Auflösung in den Feldern Position und docIDhash. Wir verwenden die relative Schriftgröße zum Rest des Dokuments hinzufügen, da Sie dies bei der Suche nicht möchten Ordnen Sie ansonsten identische Dokumente unterschiedlich, nur weil eines davon Dokumente werden in einer größeren Schriftart angezeigt.
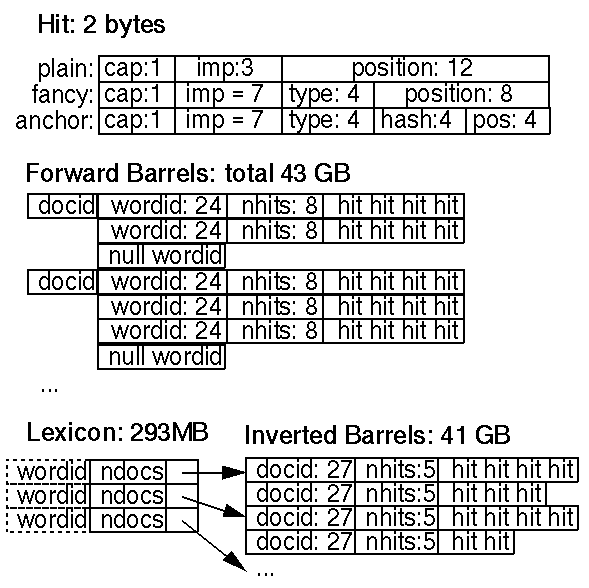 |
Die Länge einer Trefferliste wird vor den Treffern selbst gespeichert. Speichern Leerzeichen wird die Länge der Trefferliste mit der Wort-ID im Vorlauf kombiniert index und die docID im invertierten Index. Dies begrenzt es auf 8 und 5 Bit bzw. (es gibt einige Tricks, die es ermöglichen, 8 Bits auszuleihen die Wort-ID). Wenn die Länge länger ist, als so viele Bits hineinpassen würden, In diesen Bits wird ein Escape-Code verwendet, und die nächsten beiden Bytes enthalten den tatsächliche Länge.
4.2.6 Forward-Index
Der Vorwärtsindex ist tatsächlich bereits teilweise sortiert. Es ist darin gespeichert eine Reihe von Fässern (wir haben 64 verwendet). Jedes Fass enthält eine Reihe von Wort-IDs. Wenn ein Dokument Wörter enthält, die in ein bestimmtes Fass fallen, wird die docID wird im Lauf aufgezeichnet, gefolgt von einer Liste von Wort-IDs mit Trefferlisten die diesen Wörtern entsprechen. Dieses Schema erfordert etwas mehr Speicherplatz Aufgrund doppelter docIDs ist der Unterschied jedoch für einen angemessenen Zeitraum sehr gering Anzahl der Buckets und spart erheblich Zeit und Codierungskomplexität Die letzte Indexierungsphase wird vom Sortierer durchgeführt. Darüber hinaus statt zu speichern Bei den tatsächlichen Wort-IDs speichern wir jede Wort-ID als relative Differenz zur minimale Wort-ID, die in das Fass fällt, in dem sich die Wort-ID befindet. Auf diese Weise haben wir kann nur 24 Bits für die Wort-IDs in den unsortierten Fässern verwenden 8 Bit für die Trefferlistenlänge.
4.2.7 Invertierter Index
Der invertierte Index besteht aus den gleichen Fässern wie der Vorwärtsindex, außer dass sie vom Sortierer verarbeitet wurden. Für jede gültige Wort-ID gilt die Das Lexikon enthält einen Zeiger auf das Fass, in das die Wort-ID fällt. Es zeigt zu einer Doclist von docIDs zusammen mit den entsprechenden Trefferlisten. Das doclist repräsentiert alle Vorkommen dieses Worts in allen Dokumenten.
Ein wichtiger Punkt ist, in welcher Reihenfolge die docIDs im erscheinen sollen doclist. Eine einfache Lösung besteht darin, sie nach docID sortiert zu speichern. Dies erlaubt zum schnellen Zusammenführen verschiedener Dokumentlisten für mehrere Wortabfragen. Ein anderer Die Option besteht darin, sie nach der Reihenfolge des Vorkommens des Wortes sortiert zu speichern in jedem Dokument. Dies macht die Beantwortung von Ein-Wort-Fragen trivial und erleichtert Es ist wahrscheinlich, dass die Antworten auf Fragen mit mehreren Wörtern kurz vor dem Anfang stehen. Allerdings ist das Zusammenführen deutlich schwieriger. Außerdem erleichtert dies die Entwicklung erheblich schwieriger, da eine Änderung der Ranking-Funktion einen Neuaufbau erfordert des Indexes. Wir haben einen Kompromiss zwischen diesen Optionen gewählt und beibehalten zwei Sätze umgekehrter Fässer – ein Satz für Trefferlisten mit Titel oder Ankertreffer und ein weiteres Set für alle Trefferlisten. Auf diese Weise überprüfen wir die Zuerst den ersten Satz Fässer und wenn darin nicht genügend Übereinstimmungen vorhanden sind Fässer überprüfen wir die größeren.
4.3 Das Web crawlen
Das Ausführen eines Webcrawlers ist eine herausfordernde Aufgabe. Es gibt knifflige Leistungen und Zuverlässigkeitsprobleme, und was noch wichtiger ist, es gibt soziale Probleme. Crawling ist die anfälligste Anwendung, da es eine Interaktion erfordert mit Hunderttausenden Webservern und verschiedenen Nameservern, die liegen alle außerhalb der Kontrolle des Systems.
Um auf Hunderte Millionen Webseiten zu skalieren, verfügt Google über eine schnelles verteiltes Crawling-System. Ein einzelner URL-Server stellt URL-Listen bereit an eine Reihe von Crawlern (normalerweise haben wir etwa drei ausgeführt). Sowohl der URLserver und die Crawler sind in Python implementiert. Jeder Crawler hält ungefähr 300 Verbindungen gleichzeitig geöffnet. Dies ist notwendig, um Webseiten abzurufen ein ausreichend schnelles Tempo. Bei Spitzengeschwindigkeit kann das System über 100 Webseiten crawlen pro Sekunde mit vier Crawlern. Dies entspricht etwa 600.000 pro Sekunde von Dateien. Eine große Belastung für die Leistung ist die DNS-Suche. Jeder Crawler verwaltet Es verfügt über einen eigenen DNS-Cache, sodass vor dem Crawlen keine DNS-Suche durchgeführt werden muss jedes Dokument. Jede der Hunderten von Verbindungen kann eine Nummer sein unterschiedlicher Zustände: DNS suchen, Verbindung zum Host herstellen, Anfrage senden, und eine Antwort erhalten. Diese Faktoren machen den Crawler komplex Bestandteil des Systems. Es verwendet asynchrone E/A zur Verwaltung von Ereignissen und eine Reihe von Warteschlangen zum Verschieben von Seitenabrufen von Status zu Status.
Es stellt sich heraus, dass ein Crawler läuft, der eine Verbindung zu mehr als der Hälfte herstellt eine Million Server und generiert zig Millionen Protokolleinträge eine ganze Menge E-Mails und Telefonanrufe. Wegen der großen Anzahl an Menschen Wenn man online geht, gibt es immer Leute, die nicht wissen, was ein Crawler ist. denn dies ist das erste, das sie gesehen haben. Fast täglich erhalten wir eine E-Mail etwa: „Wow, du hast dir viele Seiten aus meiner Website angesehen.“ Website. Wie hat es dir gefallen?” Es gibt auch einige Leute, die es nicht wissen über die Roboter Ausschlussprotokoll und sind der Meinung, dass ihre Seite vor der Indizierung geschützt werden sollte durch eine Aussage wie „Diese Seite ist urheberrechtlich geschützt und sollte nicht indiziert werden“, Was für Webcrawler natürlich schwer zu verstehen ist. Auch, Aufgrund der riesigen Datenmenge kann es passieren, dass unerwartete Dinge passieren. Unser System hat beispielsweise versucht, ein Online-Spiel zu crawlen. Dies führte dazu viele Müllnachrichten mitten im Spiel! Es stellt sich heraus, dass dies der Fall ist war ein leicht zu behebendes Problem. Aber dieses Problem trat erst bei uns auf Dutzende Millionen Seiten heruntergeladen. Wegen der immensen Vielfalt Auf Webseiten und Servern ist es praktisch unmöglich, einen Crawler zu testen ohne es auf einem großen Teil des Internets auszuführen. Es gibt sie ausnahmslos Hunderte von obskuren Problemen, die möglicherweise nur auf einer Seite auftreten das ganze Web und führt zum Absturz des Crawlers oder, schlimmer noch, zu unvorhersehbaren Ereignissen oder falsches Verhalten. Systeme, die auf große Teile des Internets zugreifen müssen sehr robust konstruiert und sorgfältig getestet werden. Da groß Komplexe Systeme wie Crawler verursachen dort immer Probleme Es müssen erhebliche Ressourcen für das Lesen und Lösen der E-Mail aufgewendet werden diese Probleme, sobald sie auftauchen.
4.4 Indizierung des Webs
- Parsen – Jeder Parser, der für die Ausführung im gesamten Web konzipiert ist muss mit einer Vielzahl möglicher Fehler umgehen. Diese reichen von Tippfehlern in HTML-Tags in Kilobytes mit Nullen in der Mitte eines Tags, Nicht-ASCII-Zeichen, Hunderte tief verschachtelte HTML-Tags und eine Vielzahl anderer Fehler Fordern Sie die Fantasie jedes Einzelnen heraus, sich ebenso kreative Ideen auszudenken. Für maximale Geschwindigkeit verwenden wir anstelle von YACC zum Generieren eines CFG-Parsers flex, um einen lexikalischen Analysator zu generieren, den wir mit einem eigenen Stack ausstatten. Entwicklung dieses Parsers, der mit einer angemessenen Geschwindigkeit läuft und sehr robust ist war mit ziemlich viel Arbeit verbunden.
- Indizieren von Dokumenten in Fässern – nach jedem Dokument Beim Parsen wird es in mehrere Fässer codiert. Jedes Wort wird umgewandelt in eine Wort-ID mithilfe einer speicherinternen Hash-Tabelle – dem Lexikon – umwandeln. Neuzugänge zur Lexikon-Hash-Tabelle werden in einer Datei protokolliert. Sobald die Wörter konvertiert sind in WordIDs umgewandelt werden, werden ihre Vorkommen im aktuellen Dokument übersetzt in Trefferlisten erfasst und in die vorderen Läufe geschrieben. Das Wichtigste Die Schwierigkeit bei der Parallelisierung der Indexierungsphase besteht darin, dass das Lexikon muss geteilt werden. Anstatt das Lexikon zu teilen, haben wir den Ansatz gewählt ein Protokoll aller zusätzlichen Wörter zu schreiben, die nicht in einem Basislexikon enthalten waren, die wir auf 14 Millionen Wörter festgelegt haben. Auf diese Weise können mehrere Indexer ausgeführt werden parallel und dann kann die kleine Protokolldatei mit zusätzlichen Wörtern verarbeitet werden durch einen letzten Indexer.
- Sortieren – Um den invertierten Index zu generieren, benötigt der Sortierer jedes der Vorwärtsfässer und sortiert es nach Wort-ID, um ein invertiertes zu erzeugen Fass für Titel- und Ankertreffer und ein invertierter Volltextfass. Das Der Prozess erfolgt Fass für Fass und erfordert daher wenig Zwischenlagerung. Außerdem parallelisieren wir die Sortierphase, um so viele Maschinen zu nutzen, wie wir haben einfach durch den Betrieb mehrerer Sortierer, die unterschiedliche Eimer verarbeiten können gleichzeitig. Da die Fässer nicht in den Hauptspeicher passen, ist der Sortierer Unterteilt sie weiter in Körbe, die basierend auf in den Speicher passen Wort-ID und Dokument-ID. Dann lädt der Sortierer jeden Korb in den Speicher und sortiert ihn es und schreibt seinen Inhalt in das kurze umgedrehte Fass und das volle umgedrehter Lauf.
4.5 Suchen
Das Ziel der Suche besteht darin, qualitativ hochwertige Suchergebnisse effizient bereitzustellen. Viele der großen kommerziellen Suchmaschinen schienen große Fortschritte gemacht zu haben im Hinblick auf die Effizienz. Daher haben wir uns stärker auf die Qualität der Suche konzentriert in unserer Forschung, obwohl wir glauben, dass unsere Lösungen auf kommerzielle Zwecke skalierbar sind Bände mit etwas mehr Aufwand. Der Google-Abfrageauswertungsprozess ist in Abbildung 4 dargestellt.
Abbildung 4. Google-Abfrageauswertung |
Um die Antwortzeit zu begrenzen, sobald eine bestimmte Anzahl (derzeit 40.000) erreicht ist. Wenn passende Dokumente gefunden werden, geht der Sucher automatisch zu Schritt 8 in Abbildung 4. Dies bedeutet, dass es zu suboptimalen Ergebnissen kommen kann würde zurückgegeben werden. Wir untersuchen derzeit andere Möglichkeiten, dieses Problem zu lösen Problem. Früher haben wir die Treffer scheinbar nach PageRank sortiert um die Situation zu verbessern.
4.5.1 Das Ranking-System
Google verwaltet viel mehr Informationen über Webdokumente als üblich Suchmaschinen. Jede Trefferliste enthält Position, Schriftart und Großschreibung Information. Zusätzlich berücksichtigen wir Treffer aus Ankertext und den PageRank des Dokuments. Es ist schwierig, all diese Informationen zu einem Rang zusammenzufassen. Wir haben unsere Ranking-Funktion so konzipiert, dass kein bestimmter Faktor berücksichtigt werden kann zu viel Einfluss. Betrachten Sie zunächst den einfachsten Fall – eine einzelne Wortabfrage. Um ein Dokument mit einer einzelnen Wortabfrage zu bewerten, Google schaut sich die Trefferliste dieses Dokuments für dieses Wort an. Google berücksichtigt jeden hit kann einen von mehreren verschiedenen Typen haben (Titel, Anker, URL, einfacher Text). große Schriftart, einfacher Text, kleine Schriftart, …), die jeweils ihre eigene Schriftstärke haben. Die Typgewichtungen bilden einen nach Typ indizierten Vektor. Google zählt die Zahl Anzahl der Treffer jedes Typs in der Trefferliste. Dann wird jede Zählung in umgerechnet ein Zählgewicht. Die Zählgewichte steigen zunächst linear mit der Anzahl, aber Reduzieren Sie die Dosierung schnell, so dass mehr als eine bestimmte Anzahl nicht hilft. Wir nehmen das Skalarprodukt des Vektors der Zählgewichte mit dem Vektor der Typgewichte um einen IR-Score für das Dokument zu berechnen. Abschließend wird der IR-Score kombiniert mit PageRank, um dem Dokument einen endgültigen Rang zu geben.
Bei einer Suche mit mehreren Wörtern ist die Situation komplizierter. Jetzt mehrfach Trefferlisten müssen sofort durchsucht werden, damit Treffer in der Nähe auftreten Zusammen in einem Dokument werden Treffer höher gewichtet als Treffer, die weit auseinander liegen. Die Treffer aus den Mehrfachtrefferlisten werden so abgeglichen, dass nahegelegene Treffer entstehen sind aufeinander abgestimmt. Für jeden übereinstimmenden Treffersatz wird eine Nähe berechnet. Die Nähe basiert darauf, wie weit die Treffer im Dokument voneinander entfernt sind (bzw Anker), wird jedoch in 10 verschiedene Wertklassen klassifiziert, die von a reichen Phrasenübereinstimmung mit „nicht einmal annähernd“. Zählungen werden nicht nur für berechnet jede Art von Treffer, aber für jede Art und Nähe. Jede Art und Nähe Paar hat ein Typ-Prox-Gewicht. Die Zählwerte werden in Zählgewichte umgerechnet und wir nehmen das Skalarprodukt der Zählgewichte und der Typ-Prox-Gewichte um einen IR-Score zu berechnen. Alle diese Zahlen und Matrizen können alle über einen speziellen Debug-Modus mit den Suchergebnissen angezeigt werden. Diese Die Darstellungen waren bei der Entwicklung des Ranking-Systems sehr hilfreich.
4.5.2 Feedback
Die Ranking-Funktion hat viele Parameter wie die Typgewichte und die Typ-Prox-Gewichte. Die richtigen Werte für diese Parameter herauszufinden, ist so etwas wie eine schwarze Kunst. Um dies zu erreichen, haben wir ein Benutzer-Feedback Mechanismus in der Suchmaschine. Ein vertrauenswürdiger Benutzer kann optional bewerten alle Ergebnisse, die zurückgegeben werden. Dieses Feedback wird gespeichert. Dann wenn Wenn wir die Ranking-Funktion ändern, können wir die Auswirkungen dieser Änderung sehen alle vorherigen Suchanfragen, die gerankt wurden. Auch wenn dies alles andere als perfekt ist gibt uns eine Vorstellung davon, wie sich eine Änderung der Ranking-Funktion auf das auswirkt Suchergebnisse.
5 Ergebnisse und Leistung
| Frage: Bill Clinton http://www.whitehouse.gov/ 100.00% http://www.whitehouse.gov/ Büro des Präsidenten 99.67% http://www.whitehouse.gov/WH/EOP/OP/html/OP_Home.html Willkommen Zum Weißen Haus 99.98% http://www.whitehouse.gov/WH/Welcome.html Schicken E-Mail an den Präsidenten 99.86% http://www.whitehouse.gov/WH/Mail/html/Mail_President.html mailto:president@whitehouse.gov 99.98% mailto:President@whitehouse.gov 99.27% Das „Inoffizielle“ Bill Clinton 94.06% http://zpub.com/un/un-bc.html Rechnung Clinton trifft die Psychiater 86.27% http://zpub.com/un/un-bc9.html Präsident Bill Clinton – Die dunkle Seite 97.27% http://www.realchange.org/clinton.htm 3 $ Bill Clinton 94.73% |
Der wichtigste Maßstab einer Suchmaschine ist die Qualität ihrer Suchergebnisse. Während Eine vollständige Benutzerbewertung würde den Rahmen dieses Dokuments sprengen, sondern unsere eigene Erfahrung mit Google hat gezeigt, dass es bessere Ergebnisse liefert als der große Werbespot Suchmaschinen für die meisten Suchanfragen. Als Beispiel, das die Verwendung verdeutlicht Abbildung 4 zeigt die Ergebnisse von PageRank, Ankertext und Nähe für eine Suche nach „Bill Clinton“. Diese Ergebnisse zeigen einige davon Die Funktionen von Google. Die Ergebnisse werden nach Server gruppiert. Das hilft erheblich beim Durchsuchen der Ergebnismengen. Eine Reihe von Ergebnissen sind von der Domain whitehouse.gov, was man vernünftigerweise erwarten kann aus einer solchen Suche. Derzeit ist dies bei den meisten großen kommerziellen Suchmaschinen der Fall gibt keine Ergebnisse von whitehouse.gov zurück, geschweige denn die richtigen. Beachten dass es für das erste Ergebnis keinen Titel gibt. Dies liegt daran, dass dies nicht der Fall war kroch. Stattdessen stützte sich Google auf den Ankertext, um festzustellen, dass es sich um einen handelte gute Antwort auf die Frage. Ebenso ist das fünfte Ergebnis eine E-Mail-Adresse was natürlich nicht crawlbar ist. Es ist auch ein Ergebnis des Ankertextes.
Bei allen Ergebnissen handelt es sich um einigermaßen hochwertige Seiten, und bei der letzten Überprüfung stellte sich heraus, dass Es handelte sich bei keinem um defekte Links. Dies liegt vor allem daran, dass sie alle einen hohen PageRank haben. Die PageRanks sind die Prozentsätze in Rot zusammen mit Balkendiagrammen. Endlich, Es gibt keine Ergebnisse zu einem anderen Gesetzentwurf als Clinton oder zu einer Clinton außer Bill. Denn wir legen großen Wert auf die Nähe von Wortvorkommen. Natürlich ein echter Test für die Qualität einer Suchmaschine würde eine umfangreiche Benutzerstudie oder Ergebnisanalyse erfordern, was wir nicht tun Habe hier Platz. Stattdessen laden wir den Leser ein, Google selbst auszuprobieren unter http://google.stanford.edu .
5.1 Speicheranforderungen
Abgesehen von der Suchqualität ist Google darauf ausgelegt, kosteneffizient zu skalieren an die Größe des Webs anpassen, wenn es wächst. Ein Aspekt davon ist die Nutzung von Speicher effizient. Tabelle 1 enthält eine Aufschlüsselung einiger Statistiken und Speicheranforderungen von Google. Aufgrund der Komprimierung beträgt die Gesamtgröße des Repositorys etwa 53 GB, etwas mehr als ein Drittel der gesamten gespeicherten Daten. Derzeit Festplattenpreise machen das Repository zu einer relativ günstigen Quelle nützlicher Daten Daten. Noch wichtiger ist die Summe aller von der Suchmaschine verwendeten Daten erfordert eine vergleichbare Menge an Speicherplatz, etwa 55 GB. Darüber hinaus die meisten Anfragen können nur mit dem kurzen invertierten Index beantwortet werden. Mit besser Kodierung und Komprimierung des Dokumentenindex, eine hochwertige Websuche Die Engine passt möglicherweise auf ein 7-GB-Laufwerk eines neuen PCs.
|
||||||||||||||||||||||
|
||||||||||||||||||||||
5.2 Systemleistung
Für eine Suchmaschine ist es wichtig, effizient zu crawlen und zu indizieren. Das Art und Weise, wie Informationen auf dem neuesten Stand gehalten werden können, und größere Änderungen am System kann relativ schnell getestet werden. Für Google sind dies die wichtigsten Operationen Crawlen, Indizieren und Sortieren. Es ist schwierig zu messen, wie lange Das Crawlen hat insgesamt gedauert, weil die Festplatten voll waren, Nameserver abgestürzt sind oder eine Reihe anderer Probleme, die das System zum Stillstand brachten. Insgesamt hat es gedauert Das Herunterladen der 26 Millionen Seiten (einschließlich Fehlern) dauert ungefähr 9 Tage. Jedoch, Sobald das System reibungslos lief, lief es viel schneller und lud das herunter Letzte 11 Millionen Seiten in nur 63 Stunden, durchschnittlich etwas mehr als 4 Millionen Seiten pro Tag oder 48,5 Seiten pro Sekunde. Wir haben den Indexer und den Crawler ausgeführt gleichzeitig. Der Indexer lief nur schneller als die Crawler. Das ist vor allem, weil wir gerade genug Zeit damit verbracht haben, den Indexer so zu optimieren es wäre kein Engpass. Zu diesen Optimierungen gehörten Massenaktualisierungen zum Dokumentenindex und Platzierung kritischer Datenstrukturen auf dem lokale Festplatte. Der Indexer läuft mit etwa 54 Seiten pro Sekunde. Der Sortierer können komplett parallel betrieben werden; mit vier Maschinen, das Ganze Der Sortiervorgang dauert etwa 24 Stunden.
5.3 Suchleistung
Die Verbesserung der Suchleistung stand nicht im Mittelpunkt unserer Forschung Bis hierhin. Die aktuelle Version von Google beantwortet die meisten Anfragen in zwischen 1 und 10 Sekunden. Diese Zeit wird hauptsächlich von Festplatten-IO dominiert NFS (da Festplatten auf mehrere Maschinen verteilt sind). Darüber hinaus Google verfügt über keine Optimierungen wie Abfrage-Caching oder gemeinsame Subindizes Begriffe und andere gängige Optimierungen. Wir beabsichtigen, Google erheblich zu beschleunigen durch Verteilung und Hardware-, Software- und Algorithmusverbesserungen. Unser Ziel ist es, mehrere hundert Anfragen pro Sekunde bearbeiten zu können. Tabelle 2 enthält einige Beispiele für Abfragezeiten aus der aktuellen Version von Google. Sie werden wiederholt, um die Beschleunigungen anzuzeigen, die sich aus zwischengespeicherten E/A-Vorgängen ergeben.
|
||||||||||||||||||||||||||||||
6. Schlussfolgerungen
Google ist als skalierbare Suchmaschine konzipiert. Das primäre Ziel ist Bereitstellung qualitativ hochwertiger Suchergebnisse in einem schnell wachsenden weltweiten Markt Netz. Google setzt eine Reihe von Techniken ein, um die Suchqualität zu verbessern, darunter: Seitenrang, Ankertext und Näherungsinformationen. Darüber hinaus Google ist eine vollständige Architektur zum Sammeln von Webseiten, deren Indizierung und Durchführen von Suchanfragen über sie.
6.1 Zukünftige Arbeit
Eine große Websuchmaschine ist ein komplexes System und es gibt noch viel zu tun getan werden. Unsere unmittelbaren Ziele sind die Verbesserung der Sucheffizienz und die Skalierung auf etwa 100 Millionen Webseiten. Einige einfache Verbesserungen der Effizienz Dazu gehören Abfrage-Caching, Smart-Disk-Zuweisung und Subindizes. Ein anderer Ein Bereich, der viel Forschung erfordert, sind Aktualisierungen. Wir müssen intelligente Algorithmen haben um zu entscheiden, welche alten Webseiten neu gecrawlt werden sollen und welche neuen gekrochen werden. Auf dieses Ziel hin wurde in [ Cho 98 ]. Ein vielversprechendes Forschungsgebiet ist die Verwendung von Proxy-Caches zum Aufbau Suchdatenbanken, da sie nachfrageorientiert sind. Wir planen, hinzuzufügen einfache Funktionen, die von kommerziellen Suchmaschinen unterstützt werden, wie boolesche Operatoren, Verneinung und Stemmung. Andere Funktionen stehen jedoch erst am Anfang zu erforschende Aspekte wie Relevanz-Feedback und Clustering (Google derzeit unterstützt ein einfaches Hostnamen-basiertes Clustering). Wir planen auch zu unterstützen Benutzerkontext (z. B. der Standort des Benutzers) und Ergebniszusammenfassung. Wir arbeiten auch daran, die Verwendung von Linkstruktur und Linktext zu erweitern. Einfache Experimente zeigen, dass der PageRank durch Erhöhen personalisiert werden kann das Gewicht der Homepage oder der Lesezeichen eines Benutzers. Was den Linktext betrifft, sind wir es Experimentieren Sie mit der Verwendung von Text, der Links zusätzlich zum Link umgibt Text selbst. Eine Websuchmaschine ist eine sehr reichhaltige Umgebung für die Recherche Ideen. Wir haben viel zu viele, um sie hier aufzulisten, daher erwarten wir diese Zukunft nicht Der Arbeitsbereich soll in naher Zukunft deutlich kürzer werden.
6.2 Hochwertige Suche
Das größte Problem, mit dem Benutzer von Websuchmaschinen heute konfrontiert sind, ist die Qualität von den Ergebnissen, die sie zurückbekommen. Dabei sind die Ergebnisse oft amüsant und erweiterbar Sie beeinträchtigen den Horizont der Benutzer, sind oft frustrierend und kosten wertvolle Zeit. Zum Beispiel das Top-Ergebnis für eine Suche nach „Bill Clinton“ auf einem der Die beliebteste kommerzielle Suchmaschine war Bill Clinton-Witz des Tages: 14. April 1997 . Google ist darauf ausgelegt Bereitstellung einer qualitativ hochwertigeren Suche, damit das Web weiterhin schnell wächst, Informationen können leicht gefunden werden. Um dies zu erreichen, erstellt Google starker Einsatz hypertextueller Informationen, bestehend aus Linkstruktur und Linktext (Ankertext). Google verwendet außerdem Näherungs- und Schriftartinformationen. Während Die Bewertung einer Suchmaschine ist schwierig, haben wir subjektiv festgestellt dass Google qualitativ hochwertigere Suchergebnisse liefert als aktuelle Werbespots Suchmaschinen. Die Analyse der Linkstruktur mittels PageRank ermöglicht Google zur Bewertung der Qualität von Webseiten. Die Verwendung von Linktext als Die Beschreibung dessen, worauf der Link verweist, trägt dazu bei, dass die Suchmaschine relevante Ergebnisse liefert (und bis zu einem gewissen Grad qualitativ hochwertigen) Ergebnissen. Schließlich die Nutzung von Nähe Informationen tragen dazu bei, die Relevanz für viele Anfragen erheblich zu erhöhen.
6.3 Skalierbare Architektur
Abgesehen von der Qualität der Suche ist Google auf Skalierung ausgelegt. Es muss sowohl räumlich als auch zeitlich effizient sein, und konstante Faktoren sind sehr wichtig wenn es um das gesamte Web geht. Bei der Implementierung von Google haben wir gesehen Engpässe bei CPU, Speicherzugriff, Speicherkapazität, Festplattensuchen, Festplattendurchsatz, Festplattenkapazität und Netzwerk-IO. Google hat sich weiterentwickelt, um eine Reihe von Problemen zu überwinden dieser Engpässe bei verschiedenen Vorgängen. Die wichtigsten Datenstrukturen von Google Nutzen Sie den verfügbaren Lagerraum effizient. Darüber hinaus ist das Krabbeln, Indizierungs- und Sortiervorgänge sind effizient genug, um sie erstellen zu können ein Index eines wesentlichen Teils des Webs – 24 Millionen Seiten, also weniger als eine Woche. Wir gehen davon aus, dass wir einen Index von 100 Millionen Seiten aufbauen können in weniger als einem Monat.
6.4 Ein Recherchetool
Google ist nicht nur eine qualitativ hochwertige Suchmaschine, sondern auch eine Forschungsmaschine Werkzeug. Die von Google gesammelten Daten haben bereits zu vielen weiteren geführt Auf Konferenzen eingereichte Beiträge und viele weitere sind unterwegs. Aktuelle Forschung wie [ Abiteboul 97 ] hat eine Reihe von Einschränkungen gezeigt auf Anfragen zum Web, die möglicherweise beantwortet werden, ohne dass das Web verfügbar ist örtlich. Das bedeutet, dass Google (oder ein ähnliches System) nicht nur ein wertvoller ist Es handelt sich nicht um ein Forschungsinstrument, sondern um ein notwendiges Werkzeug für ein breites Anwendungsspektrum. Wir Ich hoffe, dass Google eine Ressource für Suchende und Forscher auf der ganzen Welt sein wird die Welt und wird die nächste Generation der Suchmaschinentechnologie auslösen.
7 Danksagungen
Scott Hassan und Alan Steremberg waren maßgeblich an der Entwicklung beteiligt von Google. Ihre talentierten Beiträge sind unersetzlich, ebenso wie die Autoren schulde ihnen großen Dank. Wir möchten uns auch bei Hector Garcia-Molina bedanken, Rajeev Motwani, Jeff Ullman und Terry Winograd und die gesamte WebBase-Gruppe für die Unterstützung und die aufschlussreichen Diskussionen. Endlich möchten wir um die großzügige Unterstützung unserer Gerätespender zu würdigen IBM, Intel und Sun und unsere Geldgeber. Die hier beschriebene Forschung wurde im Rahmen des Stanford durchgeführt Integriertes digitales Bibliotheksprojekt, unterstützt von der National Science Gründung im Rahmen der Kooperationsvereinbarung IRI-9411306. Finanzierung dafür Eine Kooperationsvereinbarung wird auch von DARPA und NASA sowie von Interval Research und den Industriepartnern des Stanford Digital Libraries Project geschlossen.
Verweise
- Best of the Web 1994 – Navigators http://botw.org/1994/awards/navigators.html
- Bill Clinton-Witz des Tages: 14. April 1997. http://www.io.com/~cjburke/clinton/970414.html.
- Bzip2 Homepage http://www.muraroa.demon.co.uk/
- Google-Suchmaschine http://google.stanford.edu/
- Ernte http://harvest.transarc.com/
- Mauldin, Michael L. Lycos Design-Entscheidungen in einem Internet-Suchdienst, IEEE-Experteninterview http://www.computer.org/pubs/expert/1997/trends/x1008/mauldin.htm
- Die Auswirkung der Mobiltelefonnutzung auf die Aufmerksamkeit des Fahrers http://www.webfirst.com/aaa/text/cell/cell0toc.htm
- Search Engine Watch http://www.searchenginewatch.com/
- RFC 1950 (zlib) ftp://ftp.uu.net/graphics/png/documents/zlib/zdoc-index.html
- Roboter-Ausschlussprotokoll: http://info.webcrawler.com/mak/projects/robots/exclusion.htm
- Zusammenfassung des Webwachstums: http://www.mit.edu/people/mkgray/net/web-growth-summary.html
- Yahoo! http://www.yahoo.com/
- [Abiteboul 97] Serge Abiteboul und Victor Vianu, Queries and Computation im Internet . Tagungsband der Internationalen Datenbankkonferenz Theorie. Delphi, Griechenland 1997.
- [Bagdikian 97] Ben H. Bagdikian. Das Medienmonopol . 5. Auflage. Herausgeber: Beacon, ISBN: 0807061557
- [Chakrabarti 98] S. Chakrabarti, B. Dom, D. Gibson, J. Kleinberg, P. Raghavan und S. Rajagopalan. Automatische Ressourcenzusammenstellung durch Analyse der Hyperlinkstruktur und des zugehörigen Textes. Siebte internationale Webkonferenz (WWW 98). Brisbane, Australien, 14.–18. April 1998.
- [Cho 98] Junghoo Cho, Hector Garcia-Molina, Lawrence Page. Effizient Durchsuchen der URL-Bestellung. Siebte internationale Webkonferenz (WWW 98). Brisbane, Australien, 14.–18. April 1998.
- [Gravano 94] Luis Gravano, Hector Garcia-Molina und A. Tomasic. Der Wirksamkeit von Gloss für das Problem der Textdatenbankerkennung. Proz. der 1994 ACM SIGMOD International Conference on Management Of Data, 1994.
- [Kleinberg 98] Jon Kleinberg, Maßgebliche Quellen in einem Hyperlink Umwelt , Proc. ACM-SIAM-Symposium über diskrete Algorithmen, 1998.
- [Marchiori 97] Massimo Marchiori. Die Suche nach korrekten Informationen im Web: Hyper-Suchmaschinen. Die sechste internationale WWW-Konferenz (WWW 97). Santa Clara, USA, 7.-11. April 1997.
- [McBryan 94] Oliver A. McBryan. GENVL und WWWW: Werkzeuge zur Zähmung des Netz. Erste internationale Konferenz zum World Wide Web. CERN, Genf (Schweiz), 25.-26.-27. Mai 1994. http://www.cs.colorado.edu/home/mcbryan/mypapers/www94.ps
- [Seite 98] Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd. Der PageRank Citation Ranking: Ordnung ins Web bringen. Manuskript in Fortschritt. http://google.stanford.edu/~backrub/pageranksub.ps
- [Pinkerton 94] Brian Pinkerton, Finden, was Menschen wollen: Erfahrungen mit dem WebCrawler. Die zweite internationale WWW-Konferenz Chicago, USA, 17.–20. Oktober 1994. http://info.webcrawler.com/bp/WWW94.html
- [Spertus 97] Ellen Spertus. ParaSite: Bergbaustrukturelle Informationen im Internet. Die sechste internationale WWW-Konferenz (WWW 97). Weihnachtsmann Clara, USA, 7.-11. April 1997.
- [TREC 96] Tagungsband der fünften Text REtrieval-Konferenz (TREC-5). Gaithersburg, Maryland, 20.–22. November 1996. Herausgeber: Department of Commerce, National Institute of Standards and Technology. Herausgeber: DK Harman und EM Voorhees. Vollständiger Text unter: http://trec.nist.gov/
- [Witten 94] Ian H. Witten, Alistair Moffat und Timothy C. Bell. Verwaltung Gigabyte: Dokumente und Bilder komprimieren und indizieren. New York: Van Nostrand Reinhold, 1994.
- [Weiss 96] Ron Weiss, Bienvenido Velez, Mark A. Sheldon, Chanathip Manprempre, Peter Szilagyi, Andrzej Duda und David K. Gifford. HyPursuit: Eine hierarchische Netzwerksuchmaschine, die Content-Link-Hypertext-Clustering nutzt. Tagungsband der 7. ACM-Konferenz zum Thema Hypertext. New York, 1996.
Leben


Sergey Brin erhielt seinen BS-Abschluss in Mathematik und Computer 1993 schloss er sein Studium der Naturwissenschaften an der University of Maryland in College Park ab. Derzeit ist er ist ein Ph.D. Kandidat für Informatik an der Stanford University, wo Er erhielt seinen MS im Jahr 1995. Er ist Empfänger eines National Science Graduiertenstipendium der Stiftung. Zu seinen Forschungsinteressen gehört die Suche Engines, Informationsextraktion aus unstrukturierten Quellen und Data Mining großer Textsammlungen und wissenschaftlicher Daten.
Lawrence Page wurde in East Lansing, Michigan, geboren und erhielt einen BSE in Computertechnik an der University of Michigan Ann Arbor im Jahr 1995. Derzeit ist er Ph.D. Kandidat für Informatik bei Universität in Stanford. Zu seinen Forschungsinteressen gehört der Link Struktur des Webs, Mensch-Computer-Interaktion, Suchmaschinen, Skalierbarkeit von Informationszugriffsschnittstellen und Personal Data Mining.
8 Anhang A: Werbung und Mischmotive
Derzeit das vorherrschende Geschäftsmodell für kommerzielle Suchmaschinen ist Werbung. Die Ziele des Werbegeschäftsmodells sind nicht immer gegeben entsprechen der Bereitstellung einer qualitativ hochwertigen Suche für Benutzer. Zum Beispiel in unserem Prototyp Eines der Top-Ergebnisse der Suchmaschine für Mobiltelefone ist „ The Einfluss der Mobiltelefonnutzung auf die Aufmerksamkeit des Fahrers “, eine Studie, die erklärt ausführlich die Ablenkungen und Risiken, die mit Gesprächen verbunden sind auf einem Handy während der Fahrt. Dieses Suchergebnis wurde zuerst angezeigt, weil seiner hohen Wichtigkeit, gemessen am PageRank-Algorithmus, einer Näherung von Zitierbedeutung im Internet [ Seite, 98 ]. Es ist Es ist klar, dass eine Suchmaschine Geld für die Anzeige von Mobiltelefonen nahm Telefonanzeigen hätten Schwierigkeiten, die von unserem System zurückgegebene Seite zu rechtfertigen an seine zahlenden Werbetreibenden. Aus dieser Art von Grund und historischer Erfahrung Bei anderen Medien [ Bagdikian 83 ] erwarten wir diese Werbung Finanzierte Suchmaschinen werden von Natur aus auf die Werbetreibenden ausgerichtet sein und weg von den Bedürfnissen der Verbraucher.
Da es selbst für Experten sehr schwierig ist, Suchmaschinen zu bewerten, Besonders heimtückisch ist die Voreingenommenheit von Suchmaschinen. Ein gutes Beispiel war OpenText, Berichten zufolge verkaufte sie Unternehmen das Recht, an der Börse notiert zu werden ganz oben in den Suchergebnissen für bestimmte Suchanfragen [ Marchiori 97 ]. Diese Art der Voreingenommenheit ist viel heimtückischer als Werbung, weil Es ist nicht klar, wer es „verdient“, dort zu sein, und wer bereit ist, Geld zu zahlen aufgeführt werden. Dieses Geschäftsmodell sorgte für Aufruhr, und OpenText hat es getan keine brauchbare Suchmaschine mehr. Aber weniger eklatante Voreingenommenheit ist wahrscheinlich vom Markt toleriert werden. Beispielsweise könnte eine Suchmaschine eine kleine hinzufügen Faktor auf Suchergebnisse von „freundlichen“ Unternehmen anwenden und einen Faktor subtrahieren aus Ergebnissen von Wettbewerbern. Diese Art von Voreingenommenheit ist sehr schwer zu erkennen könnte aber dennoch erhebliche Auswirkungen auf den Markt haben. Darüber hinaus Werbung Einkommen stellt oft einen Anreiz dar, Suchergebnisse von schlechter Qualität bereitzustellen. Wir haben beispielsweise festgestellt, dass eine große Suchmaschine kein großes Ergebnis zurückgibt Homepage der Fluggesellschaft, wenn der Name der Fluggesellschaft als Suchanfrage angegeben wurde. Es ist so Es kam vor, dass die Fluggesellschaft eine teure Anzeige geschaltet hatte, die mit der Suchanfrage verknüpft war so hieß es. Eine bessere Suchmaschine hätte dies nicht erforderlich gemacht Anzeige und führte möglicherweise zum Verlust der Einnahmen der Fluggesellschaft die Suchmaschine. Generell ließe sich dies aus Verbrauchersicht argumentieren Der Ansicht ist, dass je besser die Suchmaschine ist, desto weniger Werbung geschaltet wird wird benötigt, damit der Verbraucher findet, was er sucht. Das natürlich untergräbt das werbegestützte Geschäftsmodell der bestehenden Suche Motoren. Allerdings wird es immer Geld von Werbetreibenden geben, die wollen Ein Kunde möchte das Produkt wechseln oder etwas wirklich Neues haben. Wir glauben jedoch, dass das Thema Werbung genügend gemischte Anreize bietet dass es von entscheidender Bedeutung ist, eine wettbewerbsfähige Suchmaschine zu haben, die transparent ist und im akademischen Bereich.
9 Anhang B: Skalierbarkeit
9. 1 Skalierbarkeit von Google
Wir haben Google so konzipiert, dass es kurzfristig auf ein Ziel von 100 skalierbar ist Millionen Webseiten. Wir haben gerade Datenträger und Maschinen erhalten, mit denen wir grob umgehen müssen diese Menge. Alle zeitaufwändigen Teile des Systems werden parallelisiert und ungefähr lineare Zeit. Dazu gehören Dinge wie Crawler, Indexer, und Sortierer. Wir glauben auch, dass die meisten Datenstrukturen problemlos verarbeitet werden können mit der Erweiterung. Bei 100 Millionen Webseiten werden wir jedoch sehr nah dran sein im allgemeinen Betriebssystem an alle möglichen Betriebssystemgrenzen stoßen Systeme (derzeit laufen wir sowohl auf Solaris als auch auf Linux). Dazu gehören Dinge wie adressierbarer Speicher, Anzahl offener Dateideskriptoren, Netzwerk-Sockets und Bandbreite und viele andere. Wir glauben, dass die Erweiterung auf viel mehr als 100 Millionen Seiten würden die Komplexität unseres Systems enorm erhöhen.
9.2 Skalierbarkeit zentralisierter Indexierungsarchitekturen
Mit zunehmender Leistungsfähigkeit von Computern wird die Indizierung möglich eine sehr große Textmenge zu einem angemessenen Preis. Natürlich auch andere mehr Bandbreitenintensive Medien wie Videos werden wahrscheinlich immer weiter verbreitet sein. Aber weil die Kosten für die Produktion von Text im Vergleich zu ähnlichen Medien niedrig sind Video, Text dürfte weiterhin sehr allgegenwärtig bleiben. Das ist auch wahrscheinlich Bald werden wir eine Spracherkennung haben, die eine vernünftige Konvertierungsarbeit leistet Sprache in Text umwandeln und so die verfügbare Textmenge erweitern. All dies bietet erstaunliche Möglichkeiten für die zentralisierte Indizierung. Hier ist eine Veranschaulichung Beispiel. Wir gehen davon aus, dass wir alles indizieren wollen, was jeder in den USA geschrieben hat für ein Jahr. Wir gehen davon aus, dass es in den USA 250 Millionen Menschen gibt, und zwar schreibe durchschnittlich 10.000 pro Tag. Das entspricht etwa 850 Terabyte. Gehen Sie außerdem davon aus, dass die Indizierung eines Terabytes jetzt zu vertretbaren Kosten möglich ist. Wir gehen außerdem davon aus, dass die für den Text verwendeten Indexierungsmethoden linear sind. oder nahezu linear in ihrer Komplexität. Angesichts all dieser Annahmen können wir Berechnen Sie, wie lange es dauern würde, bis wir unsere 850 Terabyte indizieren könnten zu angemessenen Kosten unter der Annahme bestimmter Wachstumsfaktoren. Moores Gesetz war wurde 1965 als Verdoppelung der Prozessorleistung alle 18 Monate definiert. Es hat Dies gilt nicht nur für Prozessoren, sondern auch für andere wichtige Dinge Systemparameter wie die Festplatte. Wenn wir annehmen, dass das Mooresche Gesetz gilt Für die Zukunft brauchen wir nur noch 10 weitere Verdoppelungen oder 15 Jahre, um unser Ziel zu erreichen Ziel ist es, alles zu indizieren, wofür jeder in den USA ein Jahr lang geschrieben hat ein Preis, den sich ein kleines Unternehmen leisten könnte. Natürlich Hardware-Experten sind etwas besorgt, dass das Mooresche Gesetz in der nächsten Zeit möglicherweise nicht mehr gelten wird 15 Jahre, aber es gibt sicherlich viele interessante zentralisierte Anwendungen selbst wenn wir nur einen Teil unseres hypothetischen Beispiels erreichen.
Natürlich ein verteiltes System wie G l oss [ Gravano 94 ] oder Ernte wird oft die effizienteste und eleganteste technische Lösung zur Indizierung sein, aber Aus diesem Grund scheint es schwierig zu sein, die Welt davon zu überzeugen, diese Systeme zu nutzen der hohe Verwaltungsaufwand bei der Einrichtung einer großen Anzahl von Installationen. Natürlich ist eine drastische Reduzierung der Verwaltungskosten durchaus wahrscheinlich ist möglich. Wenn das passiert, beginnt jeder mit der Ausführung einer verteilten Version Durch das Indexierungssystem würde sich die Suche sicherlich drastisch verbessern.
Weil Menschen nur eine begrenzte Menge tippen oder sprechen können, und zwar als Computer Durch die weitere Verbesserung wird die Textindizierung noch besser skaliert als bisher. Natürlich könnte es unendlich viele maschinengenerierte Inhalte geben, Aber allein die Indizierung riesiger Mengen an von Menschen erstellten Inhalten erscheint enorm nützlich. Daher sind wir optimistisch, dass unsere zentralisierte Websuchmaschine Die Fähigkeit der Architektur, relevante Textinformationen abzudecken, wird verbessert im Laufe der Zeit und dass die Suche eine glänzende Zukunft hat.